Scan and analyze your code for origin and license
An open-source solution to run and customize scripted pipelines based on ScanCode-toolkit, the world’s most popular open-source codebase scanning engine!
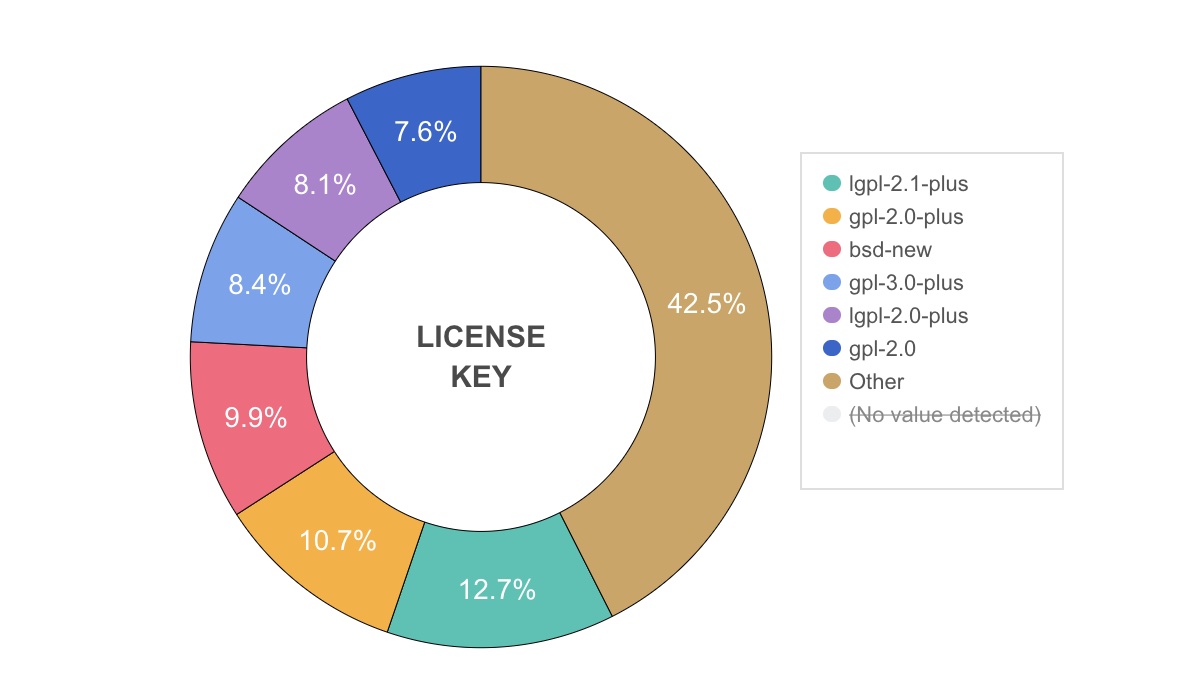
Persistent scan data
Backed by a database, ScanCode.io persists and organizes all of your scanning projects and make them accessible through a Web UI, a JSON REST API, and a command-line interface.
Made for customization
Scanning pipelines are designed to be easily extended and remixed; they can integrate many tools in an elegant, unified framework.

Apache licensed
ScanCode.io is Apache-licensed that is written in Python with Django and Django REST Framework (DRF). It has extensive documentation to help get you started and is supported by an active community of users and adopters.
ScanCode.io is a server to script and automate the process of Software Composition Analysis (SCA) to identify any open source components and their license compliance data in an application’s codebase.
ScanCode.io integrates the ScanCode-toolkit and other libraries to determine the origin and license —provenance— of open source and other third-party software using scripted pipelines. It has several applications, including Docker container and VM composition analyses, among other use cases.
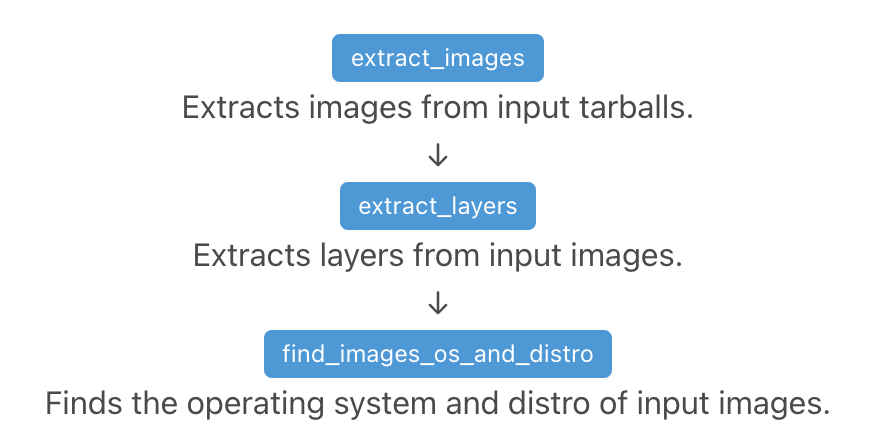
Because there is no one fits all when scanning different codebases, ScanCode.io lets you choose a scanning pipeline that fits your project needs. For example, ScanCode.io provides a specific pipeline to analyze Docker containers into its detailed file systems and application packages. It also equally handles Debian, RPM, and Alpine Linux distributions—each with its own unique characteristics—.
Further, ScanCode.io allows you to analyze a complete virtual machine image, or specifically a single application package, each with specialized pipelines.